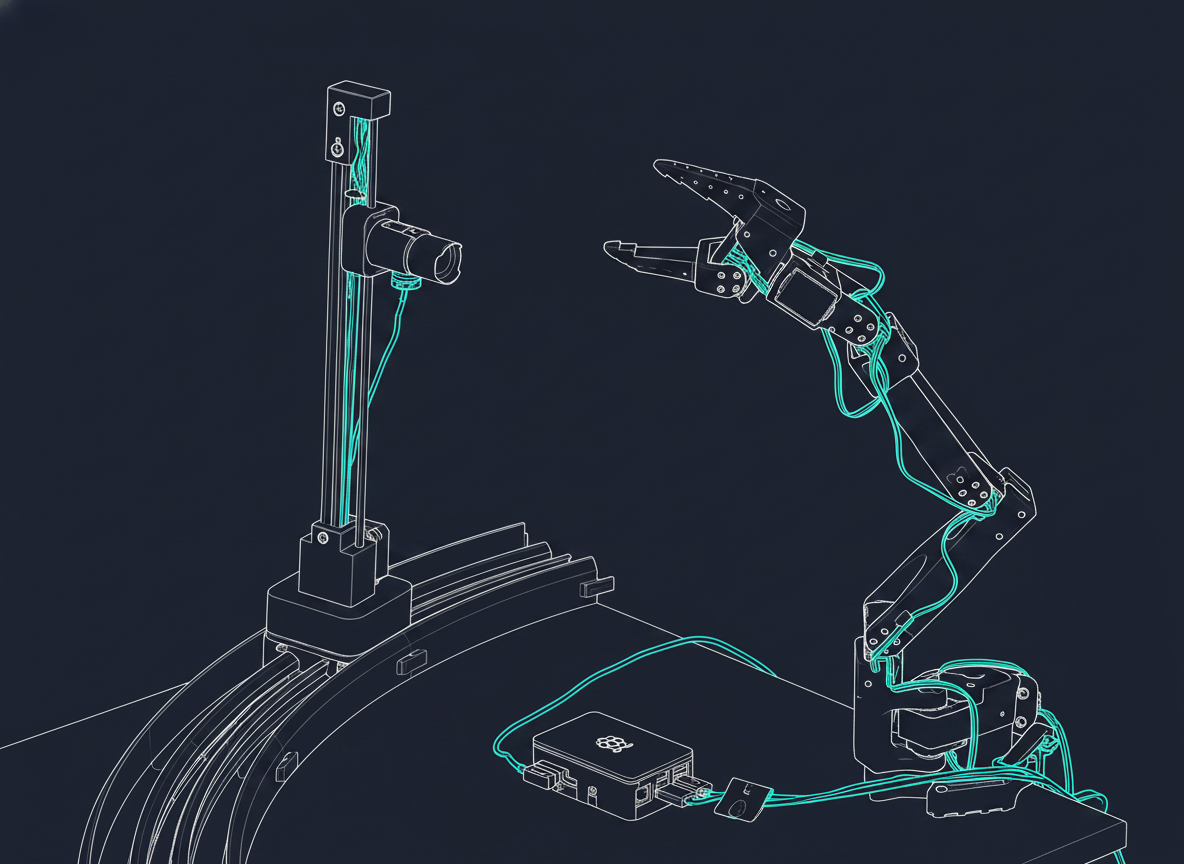
Universal agentic hardware control.
Octopus brings embedded hardware to life — automatically.
Plug in a device. Run one command. An AI coding agent reads our specs, figures out what the device is, writes the driver code, and exposes the hardware as an MCP interface that any AI agent can call.
We don't ship the code. We ship the specs and an agent that writes the code itself — on your machine, for your hardware. A new universal remote that programs itself, instead of asking you to read the manual.
curl -fsSL https://raw.githubusercontent.com/qsimeon/octopus-hw/main/install.sh | bash
Needs OPENROUTER_API_KEY exported in your shell — the agent
uses it to call models (Gemini 3 Flash, Sonnet, Kimi K2, and others; swap in
octopus.toml). Get a key at
openrouter.ai.
export OPENROUTER_API_KEY=sk-or-... before you run the install.